Wprowadzenie:
Apache Hadoop jest otwartą platformą programistyczną stworzoną w języku Java. Platforma przeznaczona jest do przetwarzania dużych ilości danych w rozproszonym środowisku, skalowalnym i rozszerzalnym horyzontalnie. Hadoop składa się z wielu komponentów, których podstawą jest HDFS (Hadoop Distributed File System), Hadoop Common (biblioteki używane przez moduły), YARN (Yet Another Resource Negotiator), MapReduce.
W ciągu wielu lat obecności na rynku platforma została rozszerzona o nowe funkcjonalności, obecnie bardzo szeroko używane, takie jak Apache Kafka, Apache Hive, Apache Spark, Apache Flume, Apache Flink. W związku ze zwiększającym się zapotrzebowaniem na skalowalne platformy, pozwalające przetwarzać znaczne zbiory danych, powstały gotowe pakiety instalacyjne zawierające kluczowe funkcjonalności, dostarczają je takie firmy, jak Hortonworks, Cloudera, MapR. W artykule skupimy się na edycji Hortonworks – pokażemy proces instalacji i konfiguracji klastra składającego sie z 3 nodów (serwerów, węzłów) oraz jednego noda sterującego.
W związku z tym, że platforma zostanie skonfigurowana w chmurze, pierwszym krokiem będzie podjęcie decyzji, której z nich użyć. Mamy do dyspozycji dużych „graczy”, takich jak AWS, Azure, Google oraz mniejsze środowiska, takie jak lokalni dostawcy. My zdecydowaliśmy się na coś pośredniego, mianowicie DigitalOcean.
DigitalOcean oferuje przyjemne, proste i cenowo przystępne środowisko konfiguracji maszyn wirtualnych. Zdecydowaliśmy się na następującą konfigurację:
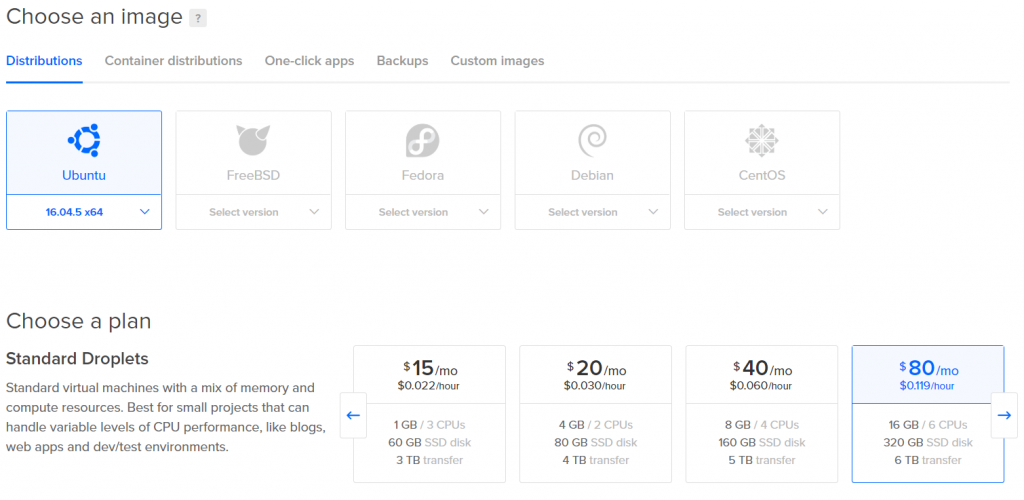
- 3 maszyny z Ubuntu 16.04 x64, 16GB Ram, 6 vCPU, 320GB za cenę 80$, przeznaczone na nody (węzły klastra)
- 1 maszyna z Ubuntu 16.04 x64, 4GB Ram, 2 vCPU, 80GB za cenę 20$, przeznaczona na komponent sterujący środowiskiem Hadoop
Podsumowując, klaster Hadoop będzie nas kosztował 260 $ miesięcznie, co można uznać za bardzo sensowną cenę, biorąc pod uwagę, że zyskujemy sporą moc obliczeniową oraz możliwość przechowywania znacznych ilości danych w ramach usługi HDFS.
Przygotowanie środowiska:
W pierwszej kolejności należy utworzyć maszyny wirtualne, które w DigitalOcean nazywają się „droplets”. Logujemy się więc do panelu sterowania i w prawym górnym rogu wybieramy Create –> Droplets, w Distributions wybieramy Ubuntu 16.04 x64 (na dzień 2019.03.03 edycja Hortonworks zawierała błędy w repozytorium, dlatego nie zdecydowaliśmy się na wersję Ubuntu 18.04.2 x64). Wybieramy parametry serwerów, które nas interesują, lokalizację datacenter region, w naszym przypadku Frankfurt, i wybieramy Create.
Przykładowa konfiguracja poniżej: